Перевод статьи Реймонда Курцвейла.
Традиционный метод проверки фактов экспертами-журналистами не позволяет справиться с огромным объемом информации, которая генерируется в интернете. Проверка фактов при помощи вычислительных алгоритмов может значительно повысить нашу способность оценивать правдивость сомнительной информации. Комплексная проверка фактов, выполненная человеком, достаточно хорошо воспроизводится алгоритмом, который находит кратчайший путь между нодами концептов при правильно установленных семантических показателях близости на графах знаний. Представленная задача может быть решена при помощи эффективных вычислительных методов. В разработке оценивается этот подход, проверяя десятки тысяч утверждений, связанных с историей, географией и биографической информацией, используя при этом открытый граф знаний, выделенный из данных, представленных в Википедии. Утверждения, независимо оцененные как истинные, получают более высокую оценку, чем ложные. Полученные результаты — значительный шаг вперед в сфере масштабируемых вычислительных методов проверки фактов, которые однажды могут быть использованы для пресечения распространения дезинформации, наносящей ущерб.
Развенчан еще один миф о том, чего «компьютеры не могут»
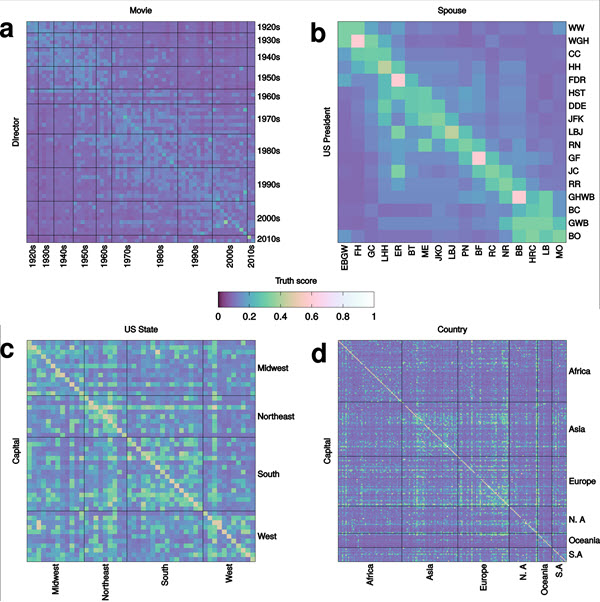
Эти графики показывают «степень правдивости» утверждений, связанных с географией, историей и развлечениями. Правдивые утверждения отображаются на диагонали, интенсивность цвета означает вероятность истинности. (Изображение: Giovanni Ciampaglia)
Теперь компьютеры способны проверить факты из любой области знаний. Так утверждают ученые из университета Индианы в публикации в издании PLoS ONE, которая появилась в открытом доступе 17 июня 2015 года.
Используя в качестве источника фактов резюме статей из Википедии*, ученые создали «граф фактов», который содержит 3 миллиона концептов и 23 миллиона связей между ними. Связь между двумя концептами можно расценивать как простое утверждение факта, например, «Сократ — человек» или «Париж — столица Франции».
При первом использовании метода ученые из университета Индианы создали простой алгоритм проверки фактов, который назначает «очки правдивости» утверждениям из области истории, географии и развлечений, а также случайным утверждениям, взятым из текстов Википедии. В ряде экспериментов автоматизированная система последовательно выдавала решения, совпадающие с «человеческой» оценкой в отношении степени точности предложенных утверждений.
Решение проблемы дезинформации
В исследовании, которое ученые описали как «викторину», команда применила алгоритм для получения ответов на простые вопросы из области географии, истории и развлечений, в том числе для попарного соединения стран или национальностей со столицей соответствующего государства, указания супругов президентов и названия фильмов, за которые оскароносные режиссеры получили награду. В большинстве тестов точность ответов была очень высокой.
Наконец, ученые использовали алгоритм для проверки отрывков из текстов Википедии, которые ранее были проверены модераторами и отмечены как истинные или ложные. В ходе эксперимента была отмечена корреляция (соответствие) между оценками степени истинности утверждения, выданными алгоритмом и человеком.
Команда ученых университета Индианы отметила, что созданный ими алгоритм может оценить правдивость утверждений, не связанных непосредственно с информацией, приведенной в инфобоксах Википедии. Например, такую цепочку фактов: Стив Тесич — сербско-американский сценарист, автор сценария классического фильма «Уходя в отрыв» - окончил университет Индианы. Эта информация не была непосредственно указана в инфобоксе статьи Википедии, посвященной Тесичу.
Использование множества источников для повышения точности информации и увеличения объема данных
«Измерение истинности утверждения в значительной степени опирается на непрямые связи, или «пути», между концептами», — говорит Джованни Лука Цимпалия (Giovanni Luca Ciampaglia, доктор наук, проходящий стажировку в Центре исследования комплексных сетей и систем в Блумингтонской школе информатики и вычислений при университете Индианы), который возглавлял исследовательскую группу.
«Если мы запрещали алгоритму для проверки фактов проходить многочисленные узлы графов, он работал плохо, поскольку не мог найти релевантные непрямые связи», - говорит Цимпалия. - «Но поскольку он способен выходить за пределы информации, представленной в единственном инфобоксе, наш метод использует возможности всего графа знаний».
«Эти результаты обнадеживают и захватывают. Мы живет в эпоху информационной перегрузки, значительная часть информации является ложной, например, необоснованные слухи и теории заговоров, которые в огромном количестве обрушиваются на журналистов и общество. Наши эксперименты показывают, как превратить жизненно важную и сложную человеческую задачу проверки фактов в проблему сетевого анализа, которую легко решить путем вычислений».
Расширение базы знаний
Хотя эксперименты проводились с использованием Википедии, метод команды ученых из университета Индианы не привязан к конкретному источнику данных. Ученые намерены провести дополнительные эксперименты с использованием графов, построенных на основе других источников знаний, например, Freebase, открытой базы знаний, созданной Google. Исследователи отмечают, что несколько баз знаний могут использоваться одновременно для учета различных систем.
Команда добавила значительное число исследований обработки естественных языков. Но ученые также отмечают, что до представления общественности результатов в виде программного обеспечения нужно проделать дополнительную работу.
Работу исследователей поддержали Швейцарский национальный научный фонд, Фонд Джеймса С. Мак-Доннела, Национальный научный фонд и Министерство обороны США.
* Команда ученых выбрала Википедию в качестве источника информации для эксперимента из-за широты представленных областей знаний и открытости данных. Хотя Википедия точна не на все 100 процентов, предыдущие исследования показали, что онлайн-энциклопедия почти так же точна, как традиционные, но охватывает намного больше тем.